# TransferQueue 数据系统
最后更新时间:2025年9月28日。
本文档介绍 [TransferQueue](https://github.com/TransferQueue/TransferQueue),一个用于高效训练后(post-training)的异步流式数据管理系统。
概述
TransferQueue 是一个高性能的数据存储和传输系统,具备全景数据可见性和流式调度能力,专为优化训练后工作流中的数据流而设计。
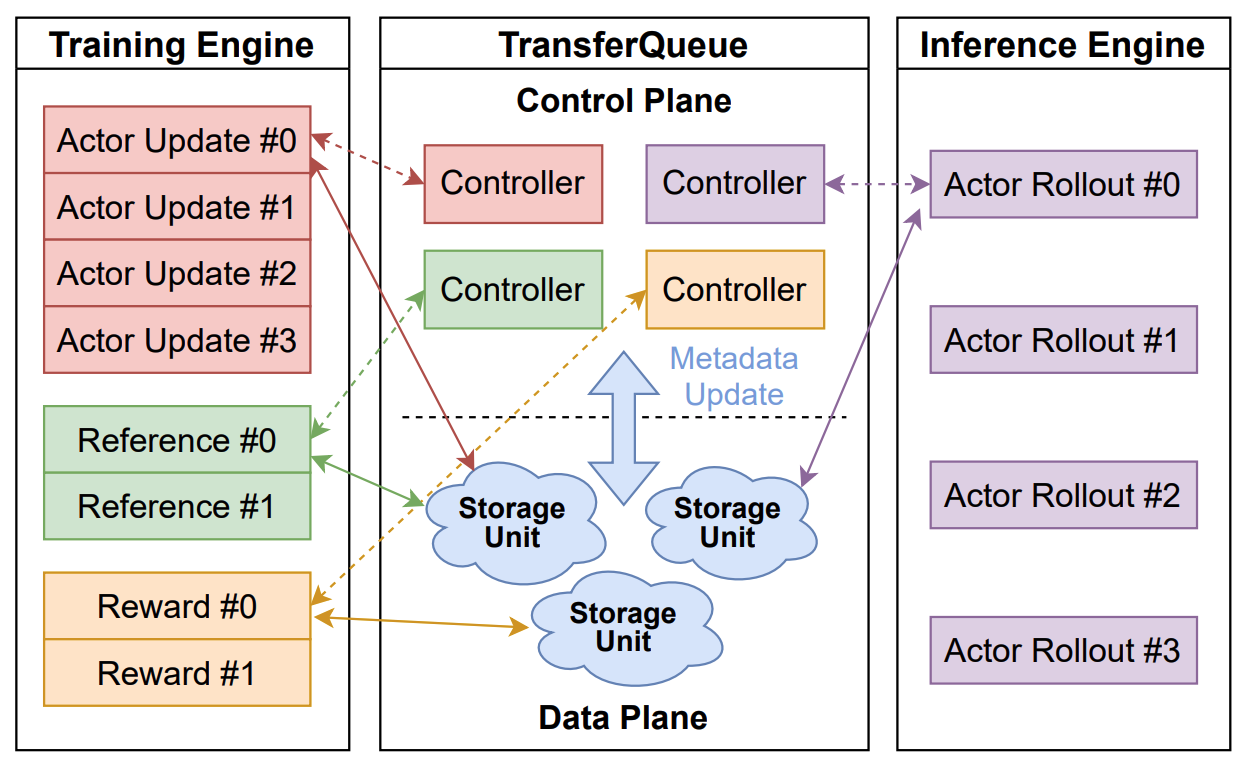
TransferQueue 提供了**细粒度的、样本级别的**数据管理能力,充当数据网关,解耦了计算任务之间显式的数据依赖。这支持了一种分而治之(divide-and-conquer)的方法,极大地简化了算法控制器的设计。
组件
### 控制平面:全景数据管理
在控制平面,`TransferQueueController` 将每个训练样本的**生产状态**和**消费状态**作为元数据进行跟踪。当所有必需的数据字段都准备就绪(即已写入 `TransferQueueStorage`)时,我们就知道该数据样本可以被下游任务消费。
对于消费状态,我们记录了每个计算任务(例如 `generate_sequences`、`compute_log_prob` 等)的消费记录。因此,即使不同的计算任务需要相同的数据字段,它们也可以独立消费数据,互不干扰。
> 未来,我们计划在控制平面支持**负载均衡**和**动态批处理**功能。此外,我们将支持分离式框架(disaggregated frameworks)的数据管理,其中每个进程自行管理数据检索,而不是由单个控制器协调。
### 数据平面:分布式数据存储
在数据平面,`TransferQueueStorageSimpleUnit` 作为基于 CPU 内存的简易存储单元,负责数据的实际存储和检索。每个存储单元可以部署在不同的节点上,实现分布式数据管理。
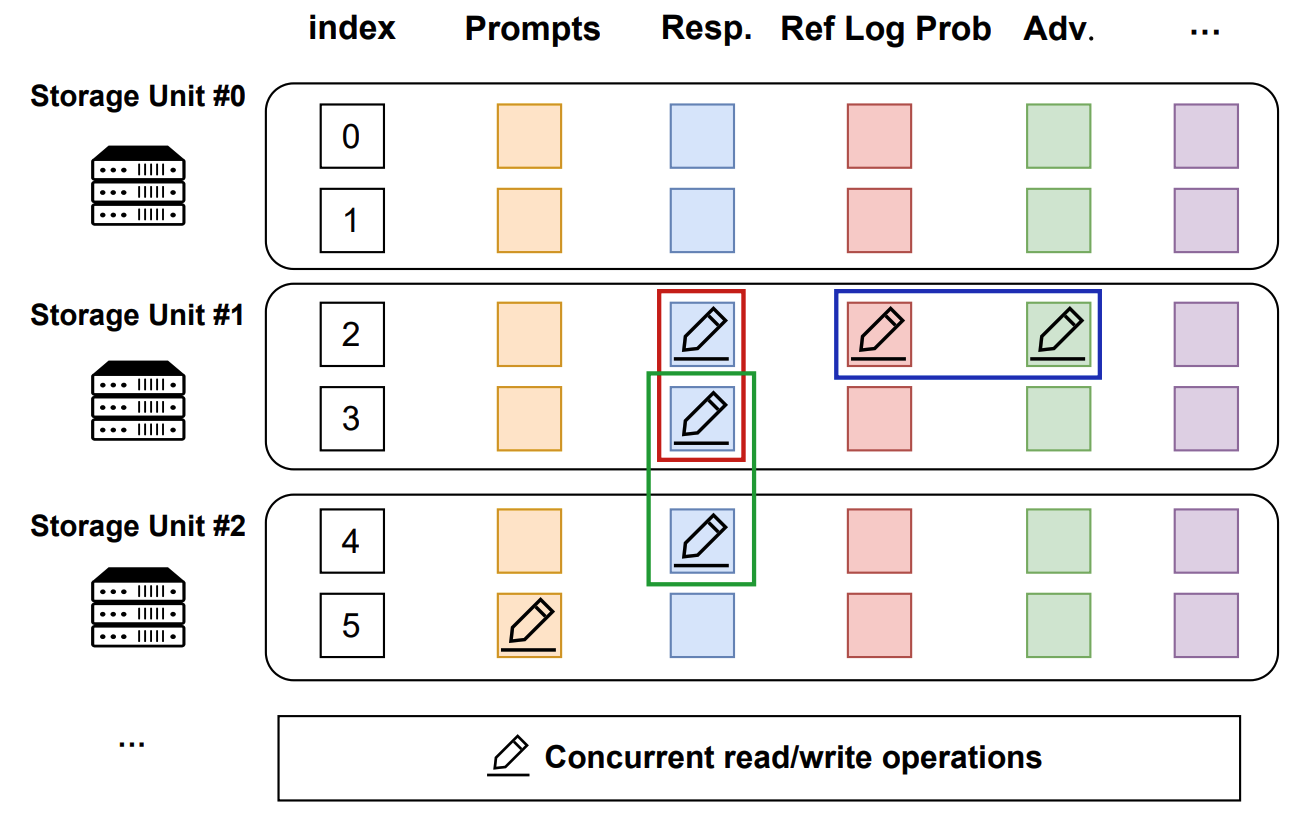
`TransferQueueStorageSimpleUnit` 采用如下的二维数据结构:
- 每一行代表一个训练样本,在相应的全局批次中分配有唯一索引。
- 每一列代表计算任务的输入/输出数据字段。
这种数据结构设计源于训练后流程的计算特性,其中每个训练样本在任务管道中以接力(relayed)方式生成。它提供了精确的寻址能力,允许以流式方式进行细粒度的、并发的数据读写操作。
> 未来,我们计划实现一个**通用的存储抽象层**,以支持各种存储后端。通过这个抽象,我们希望能集成高性能存储解决方案,如 [MoonCakeStore](https://github.com/kvcache-ai/Mooncake),以支持通过 RDMA 进行设备到设备的数据传输,进一步提高大规模数据的传输效率。
### 用户接口:异步与同步客户端
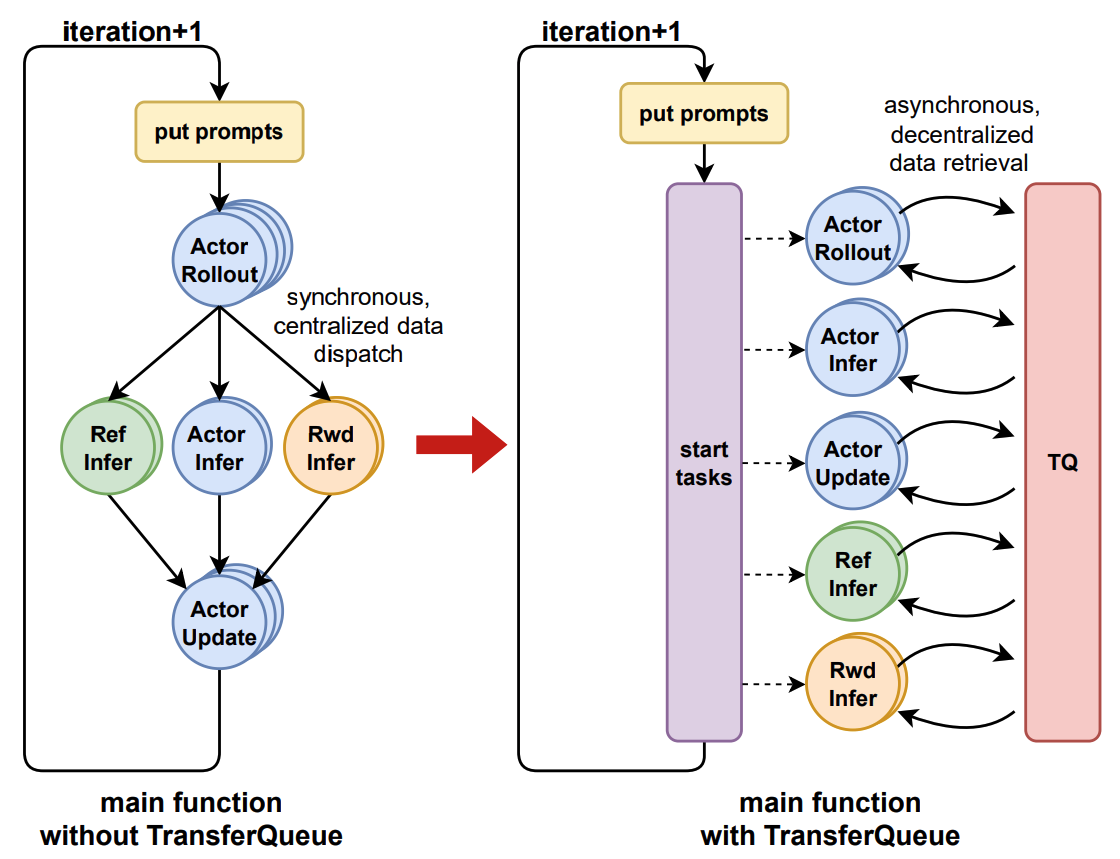
TransferQueue 系统的交互工作流程如下:
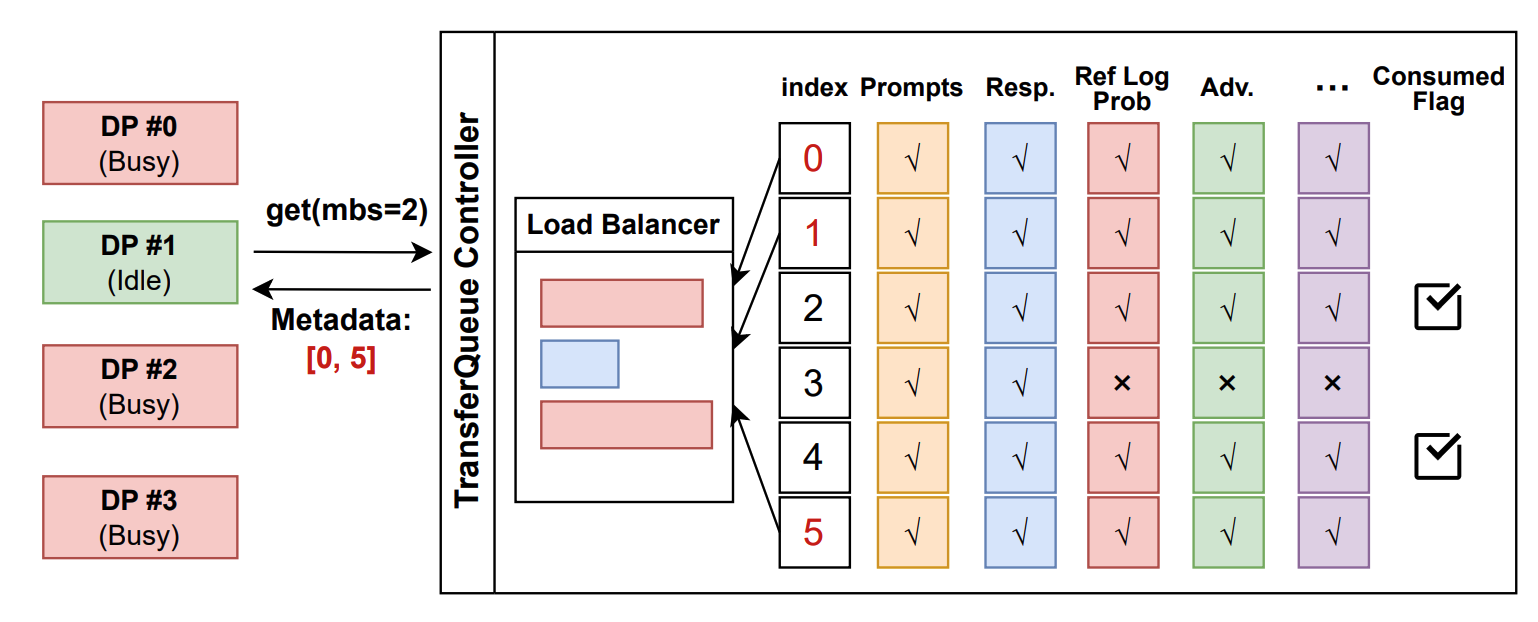
1. 进程向 `TransferQueueController` 发送读取请求。
2. `TransferQueueController` 扫描每个样本(行)的生产和消费元数据,并根据负载均衡策略动态组装微批次元数据。该机制支持样本级别的数据调度。
3. 进程使用控制器提供的元数据从分布式存储单元检索实际数据。
为简化 TransferQueue 的使用,我们已将其封装为 `AsyncTransferQueueClient` 和 `TransferQueueClient`。这些客户端同时提供异步和同步接口用于数据传输,使用户可以轻松地将 TransferQueue 集成到他们的框架中。
> 未来,我们将提供一个 `StreamingDataLoader` 接口,用于前面在 [RFC#2662](https://github.com/volcengine/verl/discussions/2662) 中讨论的分离式框架。利用这个抽象,每个进程可以像 PyTorch 中的 `DataLoader` 一样自动获取自己的数据。TransferQueue 系统将处理不同并行策略导致的底层数据调度和传输逻辑,大大简化分离式框架的设计。
案例展示
### 通用用法
主要的交互点是 `AsyncTransferQueueClient` 和 `TransferQueueClient`,它们充当与 TransferQueue 系统的通信接口。
核心接口:
- (async_)get_meta(data_fields: list[str], batch_size:int, global_step:int, get_n_samples:bool, task_name:str) -> BatchMeta
- (async_)get_data(metadata:BatchMeta) -> TensorDict
- (async_)put(data:TensorDict, metadata:BatchMeta, global_step)
- (async_)clear(global_step: int)
我们将很快发布详细的教程和 API 文档。
### verl 示例
目前将 TransferQueue 集成到 verl 的主要动机是**缓解单个控制器 `RayPPOTrainer` 的数据传输瓶颈**。当前,所有 `DataProto` 对象都必须通过 `RayPPOTrainer` 路由,导致整个训练后系统成为单点瓶颈。
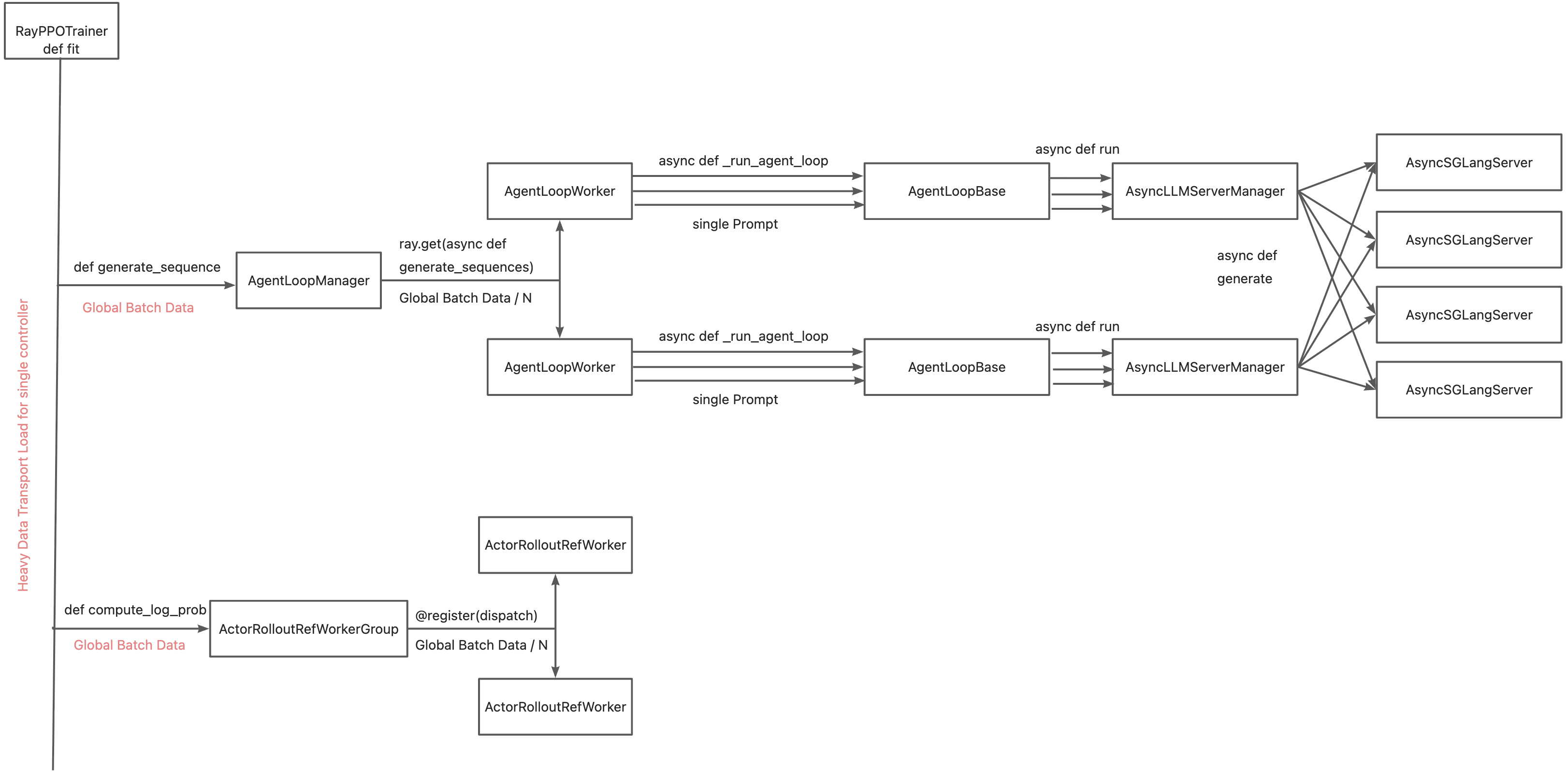
利用 TransferQueue,我们通过以下方式将体验数据传输与元数据分发分离开:
- 将 `DataProto` 替换为 `BatchMeta`(元数据)和 `TensorDict`(实际数据)结构
- 通过 `BatchMeta` 保留 verl 原有的分发/收集逻辑(保持单控制器可调试性)
- 通过 TransferQueue 的分布式存储单元加速数据传输
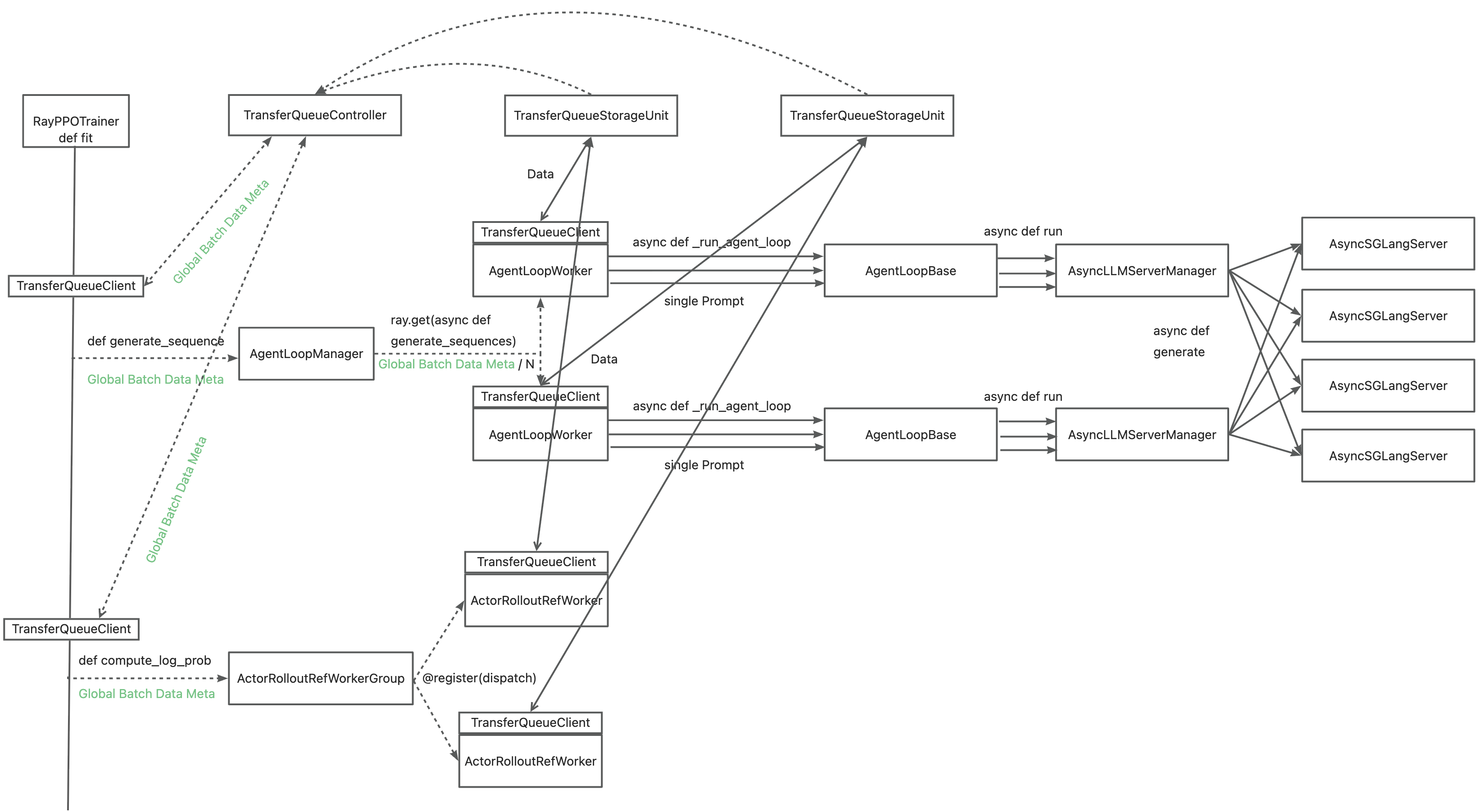
您可能需要参考 [recipe](https://github.com/TransferQueue/TransferQueue/tree/dev/recipe/simple_use_case),其中我们模拟了异步和同步场景下的 verl 用法。
引用
如果您发现此仓库有用,请引用我们的论文:
```bibtex
@article{han2025asyncflow,
title={AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training},
author={Han, Zhenyu and You, Ansheng and Wang, Haibo and Luo, Kui and Yang, Guang and Shi, Wenqi and Chen, Menglong and Zhang, Sicheng and Lan, Zeshun and Deng, Chunshi and others},
journal={arXiv preprint arXiv:2507.01663},
year={2025}
}
```