
Benchmarking a Model¶
您是否曾训练过多个检测模型,并想知道哪一个在您的特定用例中表现最佳?或者,您下载了一个预训练模型,并想在您的数据集上验证其性能?模型基准测试是做出有关在生产环境中部署哪个模型的明智决策的关键。
本指南将展示一种使用 supervision 基准测试结果的便捷方法。它将涵盖:
本指南将使用一个实例分割模型,但它也适用于目标检测、实例分割和定向边界框模型(OBB)。
本指南的精简版本可在 Colab Notebook 中找到。
加载数据集¶
假设您有一个数据集。您可能在 Universe 上找到它;或者您可能标注了自己的数据。无论哪种情况,本指南假设您手头有一个已标注的数据集。
我们将使用以下库:
roboflow用于管理数据集和部署模型inference用于运行模型supervision用于评估模型结果
pip install roboflow supervision
pip install git+https://github.com/roboflow/inference.git@linas/allow-latest-rc-supervision
Info
我们目前正在更新 inference。请按照所示方式安装它。
以下是如何下载数据集:
from roboflow import Roboflow
rf = Roboflow(api_key="<YOUR_API_KEY>")
project = rf.workspace("<WORKSPACE_NAME>").project("<PROJECT_NAME>")
dataset = project.version(<DATASET_VERSION_NUMBER>).download("<FORMAT>")
如果您的数据集来自 Universe,请转到 Dataset > Download Dataset > 选择格式(例如 YOLOv11)> Show download code。
如果您自己标注数据,请转到仪表板并查看本指南以查找您的工作区和项目 ID。
在本指南中,我们将使用一个小的 Corgi v2 数据集。它标注良好,并附带了一个测试集。
from roboflow import Roboflow
rf = Roboflow(api_key="<YOUR_API_KEY>")
project = rf.workspace("fbamse1-gm2os").project("corgi-v2")
dataset = project.version(4).download("yolov11")
这将在当前工作目录中创建一个名为 Corgi-v2-4 的文件夹,其中包含 train、test 和 valid 文件夹以及一个 data.yaml 文件。
加载模型¶
让我们加载一个模型。
基准测试基础¶
评估您的模型需要仔细选择数据集。您应该使用哪些图像?让我们仔细研究一下不同的场景。
- 不相关的数据集:如果您有一个未用于训练模型的日期集,这是最佳选择。
- 训练集:这是用于训练模型的图像集。如果模型未在此数据集上训练,则此方法可用。否则,切勿将其用于基准测试 - 结果看起来会好得不切实际。
- 验证集:这是在训练期间用于验证模型的图像集。每 N 个训练 epoch,模型将在验证集上进行评估。通常,模型训练会停止,直到验证损失停止改进。因此,即使图像未用于训练模型,它仍然间接影响训练结果。
- 测试集:这是为模型测试保留的图像集。这正是您应该用于基准测试的集合。如果数据集已正确拆分,模型在训练期间不会看到这些图像中的任何一个。
因此,不相关的数据集或 test 集是基准测试的最佳选择。
还可能出现其他几个问题:
- 额外类别:不相关的数据集可能包含您需要过滤掉的其他类别,然后再计算指标。
- 类别不匹配:在不相关的数据集中,类别名称或 ID 可能与模型生成的名称或 ID 不同,您需要重新映射它们,这在本指南中有说明。
- 数据污染:
test集可能未正确拆分,测试集中的图像也存在于training或validation集并用于训练。在这种情况下,结果将过于乐观。当训练和测试使用非常相似的图像时,也会出现这种情况 - 例如,在相同的环境、相同的照明条件、相似的角度等条件下拍摄的图像。 - 缺少测试集:某些数据集不附带测试集。在这种情况下,您应该收集并标注您自己的数据。或者,可以使用验证集,但结果可能会过于乐观。请务必尽快在实际环境中进行测试。
运行模型¶
此时,您应该已:
- 一个包含已标注图像的数据集供评估模型。
- 一个已准备好进行基准测试的模型。
准备好这些之后,我们就可以运行模型并获得预测。
我们将使用 supervision 创建一个数据集迭代器,然后对每个图像运行模型。
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml"
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model.infer(image)[0]
predictions = sv.Detections.from_inference(result)
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml"
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model(image)[0]
predictions = sv.Detections.from_ultralytics(result)
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
重新映射类别¶
您是否注意到上面逻辑中的问题? 由于我们使用了一个不相关的数据集,类别名称和 ID 可能与模型训练时使用的不同。
我们需要重新映射它们,以匹配数据集的类别。方法如下:
def remap_classes(
detections: sv.Detections,
class_ids_from_to: dict[int, int],
class_names_from_to: dict[str, str]
) -> None:
new_class_ids = [
class_ids_from_to.get(class_id, class_id) for class_id in detections.class_id]
detections.class_id = np.array(new_class_ids)
new_class_names = [
class_names_from_to.get(name, name) for name in detections["class_name"]]
predictions["class_name"] = np.array(new_class_names)
我们还要删除不在数据集类别中的预测。
可以在 data.yaml 文件中找到数据集类别名称和 ID,或通过打印 dataset.classes 来查看。
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml"
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model.infer(image)[0]
predictions = sv.Detections.from_inference(result)
remap_classes(
detections=predictions,
class_ids_from_to={16: 0},
class_names_from_to={"dog": "Corgi"}
)
predictions = predictions[
np.isin(predictions["class_name"], test_set.classes)
]
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
可以在 data.yaml 文件中找到数据集类别名称和 ID,或通过打印 dataset.classes 来查看。
每个模型将具有不同的类别映射,因此请务必检查模型的文档。在本例中,模型是在 COCO 数据集上训练的,其类别配置可在此处找到。
import supervision as sv
test_set = sv.DetectionDataset.from_yolo(
images_directory_path=f"{dataset.location}/test/images",
annotations_directory_path=f"{dataset.location}/test/labels",
data_yaml_path=f"{dataset.location}/data.yaml"
)
image_paths = []
predictions_list = []
targets_list = []
for image_path, image, label in test_set:
result = model(image)[0]
predictions = sv.Detections.from_ultralytics(result)
remap_classes(
detections=predictions,
class_ids_from_to={16: 0},
class_names_from_to={"dog": "Corgi"}
)
predictions = predictions[
np.isin(predictions["class_name"], test_set.classes)
]
image_paths.append(image_path)
predictions_list.append(predictions)
targets_list.append(label)
可视化预测¶
评估模型性能的第一步是可视化其预测结果。 这可以直观地了解您的模型检测对象的程度以及它可能在哪些方面出现故障。
import supervision as sv
N = 9
GRID_SIZE = (3, 3)
target_annotator = sv.PolygonAnnotator(color=sv.Color.from_hex("#8315f9"), thickness=8)
prediction_annotator = sv.PolygonAnnotator(color=sv.Color.from_hex("#00cfc6"), thickness=6)
annotated_images = []
for image_path, predictions, targets in zip(
image_paths[:N], predictions_list[:N], targets_list[:N]
):
annotated_image = cv2.imread(image_path)
annotated_image = target_annotator.annotate(scene=annotated_image, detections=targets)
annotated_image = prediction_annotator.annotate(scene=annotated_image, detections=prediction)
annotated_images.append(annotated_image)
sv.plot_images_grid(images=annotated_images, grid_size=GRID_SIZE)
在此,紫色中的预测是目标(真实情况),而青色中的预测是模型预测。
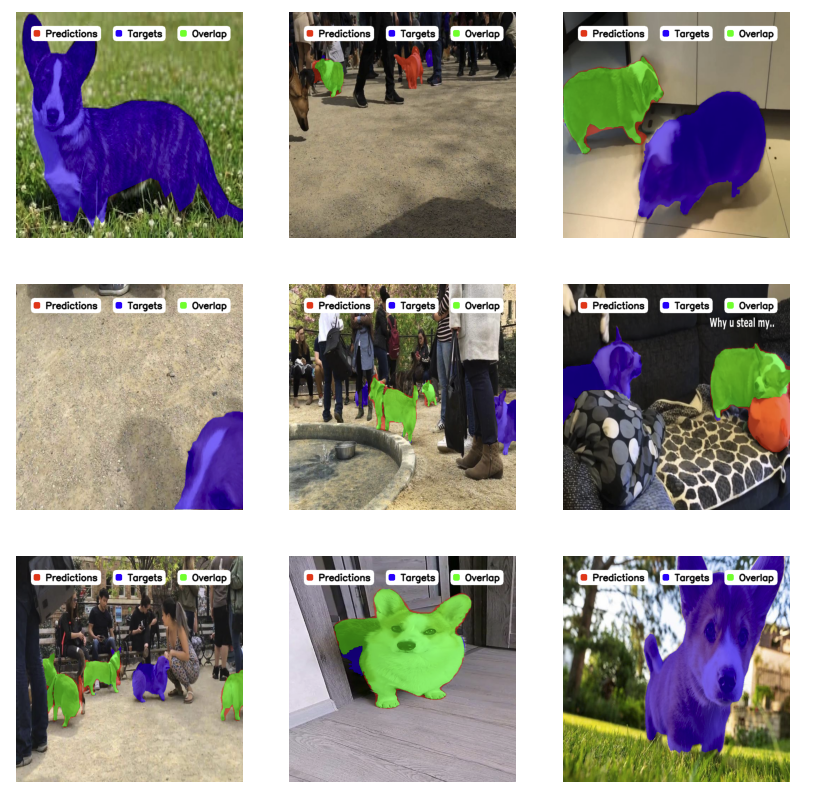
基准测试指标¶
有了多个模型,细节很重要。目视检查可能不够。supervision 提供了一系列指标,可帮助获得模型性能的精确数值结果。
平均精度均值 (mAP)¶
我们将从平均精度均值 (mAP) 开始,这是目标检测最常用的指标。它衡量所有类别和 IoU 阈值的平均精度。
有关详细说明,请查看我们的博客和YouTube 视频。
在这里,最常用的值是 mAP 50:95。它表示所有类别和 IoU 阈值(从 0.5 到 0.95)的平均精度,而其他值如 mAP 50 或 mAP 75 仅考虑单个 IoU 阈值(分别为 0.5 和 0.75)。
让我们计算 mAP:
from supervision.metrics import MeanAveragePrecision, MetricTarget
map_metric = MeanAveragePrecision(metric_target=MetricTarget.MASKS)
map_result = map_metric.update(predictions_list, targets_list).compute()
尝试打印结果以一目了然地查看:
MeanAveragePrecisionResult:
Metric target: MetricTarget.MASKS
Class agnostic: False
mAP @ 50:95: 0.2409
mAP @ 50: 0.3591
mAP @ 75: 0.2915
mAP scores: [0.35909 0.3468 0.34556 ...]
IoU thresh: [0.5 0.55 0.6 ...]
AP per class:
0: [0.35909 0.3468 0.34556 ...]
...
Small objects: ...
Medium objects: ...
Large objects: ...
您也可以绘制结果:
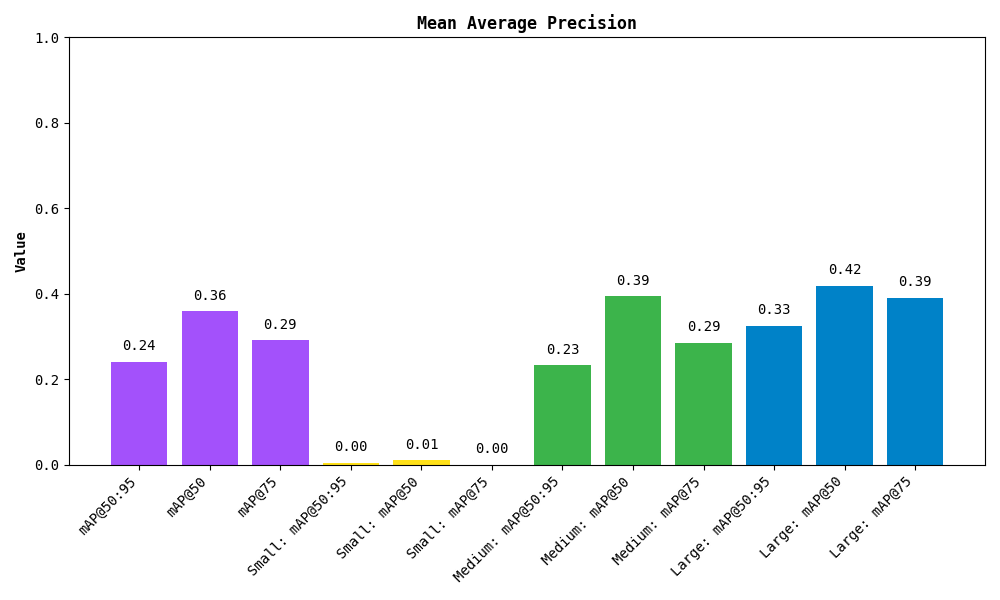
该指标还可以细分按检测对象区域划分的结果。Small(小)、Medium(中)和 Large(大)分别只需面积小于 32²、介于 32² 和 96² 之间以及大于 96² 像素即可。
F1 分数¶
F1 分数是另一个有用的指标,尤其是在处理假阳性和假阴性之间的不平衡时。它是精确率(预测正确的数量)和召回率(检测到的实际实例数量)的调和平均值。
以下是计算 F1 分数的方法:
from supervision.metrics import F1Score, MetricTarget
f1_metric = F1Score(metric_target=MetricTarget.MASKS)
f1_result = f1_metric.update(predictions_list, targets_list).compute()
与 mAP 一样,您也可以打印结果:
F1ScoreResult:
Metric target: MetricTarget.MASKS
Averaging method: AveragingMethod.WEIGHTED
F1 @ 50: 0.5341
F1 @ 75: 0.4636
F1 @ thresh: [0.53406 0.5278 0.52153 ...]
IoU thresh: [0.5 0.55 0.6 ...]
F1 per class:
0: [0.53406 0.5278 0.52153 ...]
...
Small objects: ...
Medium objects: ...
Large objects: ...
同样,您也可以绘制结果:
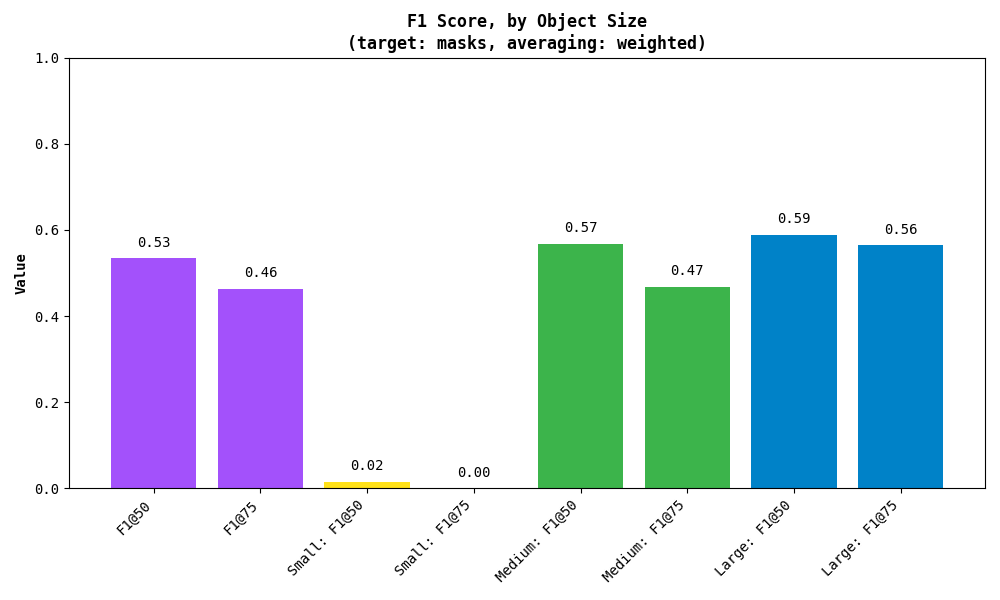
与 mAP 一样,该指标还可以细分按检测对象区域划分的结果。Small(小)、Medium(中)和 Large(大)分别只需面积小于 32²、介于 32² 和 96² 之间以及大于 96² 像素即可。
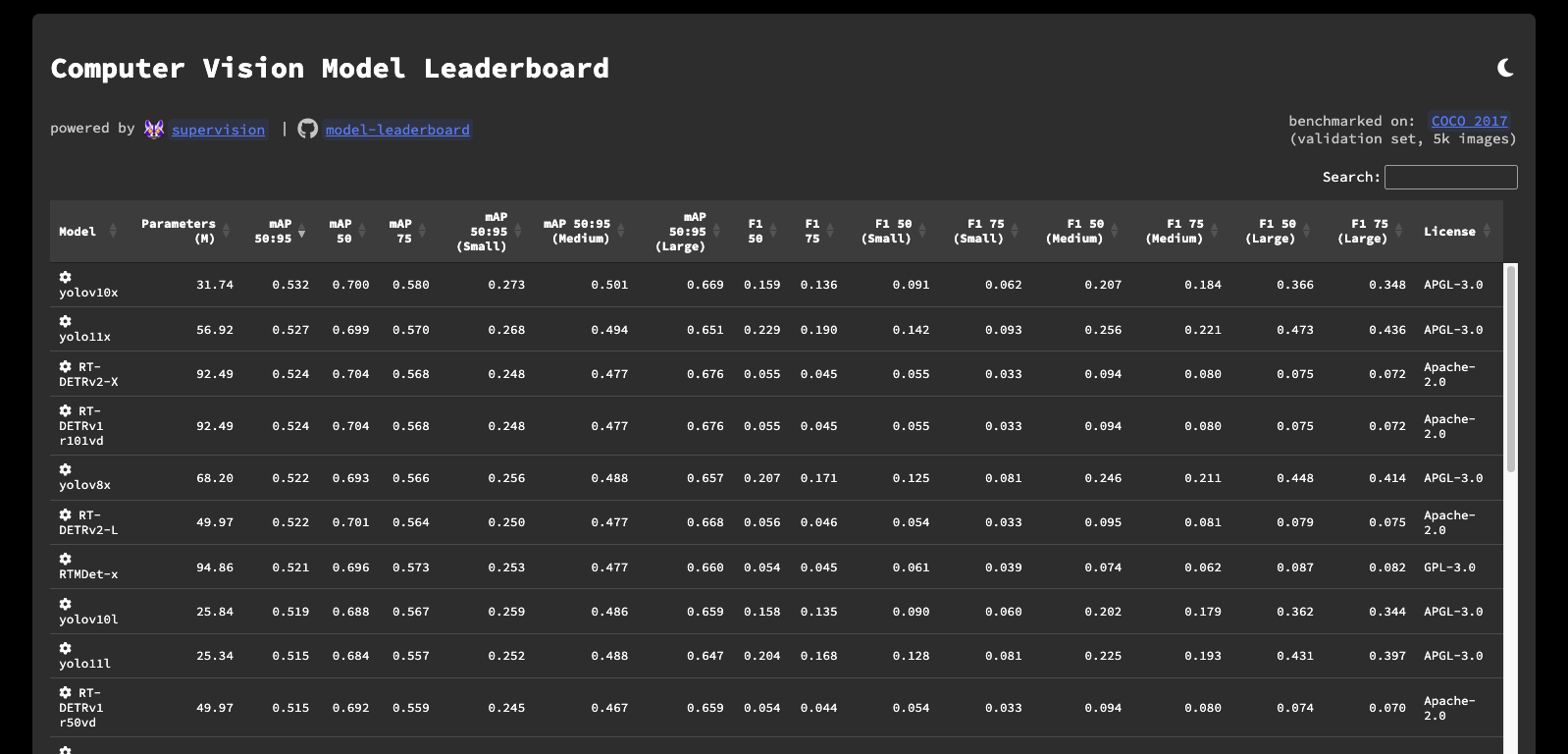
模型排行榜¶
想比较基础模型吗?我们已为您准备好。请查看我们的模型排行榜,了解不同模型的表现,并了解最先进的结果。这是一个了解领先模型能达到什么水平的好地方,也可以比较您自己的结果。
更好的是,该存储库是开源的!您可以查看模型的基准测试方式,自己运行评估,甚至可以将自己的模型添加到排行榜中。请查看GitHub 上的内容!
结论¶
在本指南中,您学习了如何设置环境、训练或使用预训练模型、可视化预测并使用 mAP、F1 分数 等指标评估模型性能,并了解了我们的模型排行榜。
本指南的精简版本也可在Colab Notebook 中找到。
有关更多详细信息,请务必查看我们的文档 并加入我们的社区讨论。如果您发现任何问题,请在 GitHub 上告知我们。
祝您的基准测试一切顺利!