Tokens
现代大型语言模型(LLMs)通常基于一种处理称为 token 的单元序列的 transformer 架构。Tokens 是模型用来分解输入和生成输出的基本元素。在本节中,我们将讨论什么是 token 以及语言模型如何使用它们。
什么是 token?
Token 是语言模型读取、处理和生成的单位。这些单元可能因模型提供商的定义方式而异,但总的来说,它们可以代表:
- 一个完整的单词(例如,“apple”),
- 一个单词的一部分(例如,“app”),
- 或其他语言成分,如标点符号或空格。
模型如何对输入进行分词取决于其 tokenizer 算法,该算法将输入转换为 tokens。同样,模型的输出也是一个 token 流,然后会被解码回人类可读的文本。
token 在语言模型中如何工作
语言模型使用 tokens 的原因与其对语言的理解和预测方式有关。语言模型不是直接处理字符或整个句子,而是关注 tokens,它们代表有意义的语言单元。处理过程如�下:
-
输入分词:当您向模型提供一个提示(例如,“LangChain is cool!”)时,分词算法会将文本分解成 tokens。例如,这个句子可以被分词成类似
["Lang", "Chain", " is", " cool", "!"]的部分。请注意,token 的边界不一定与单词的边界对齐。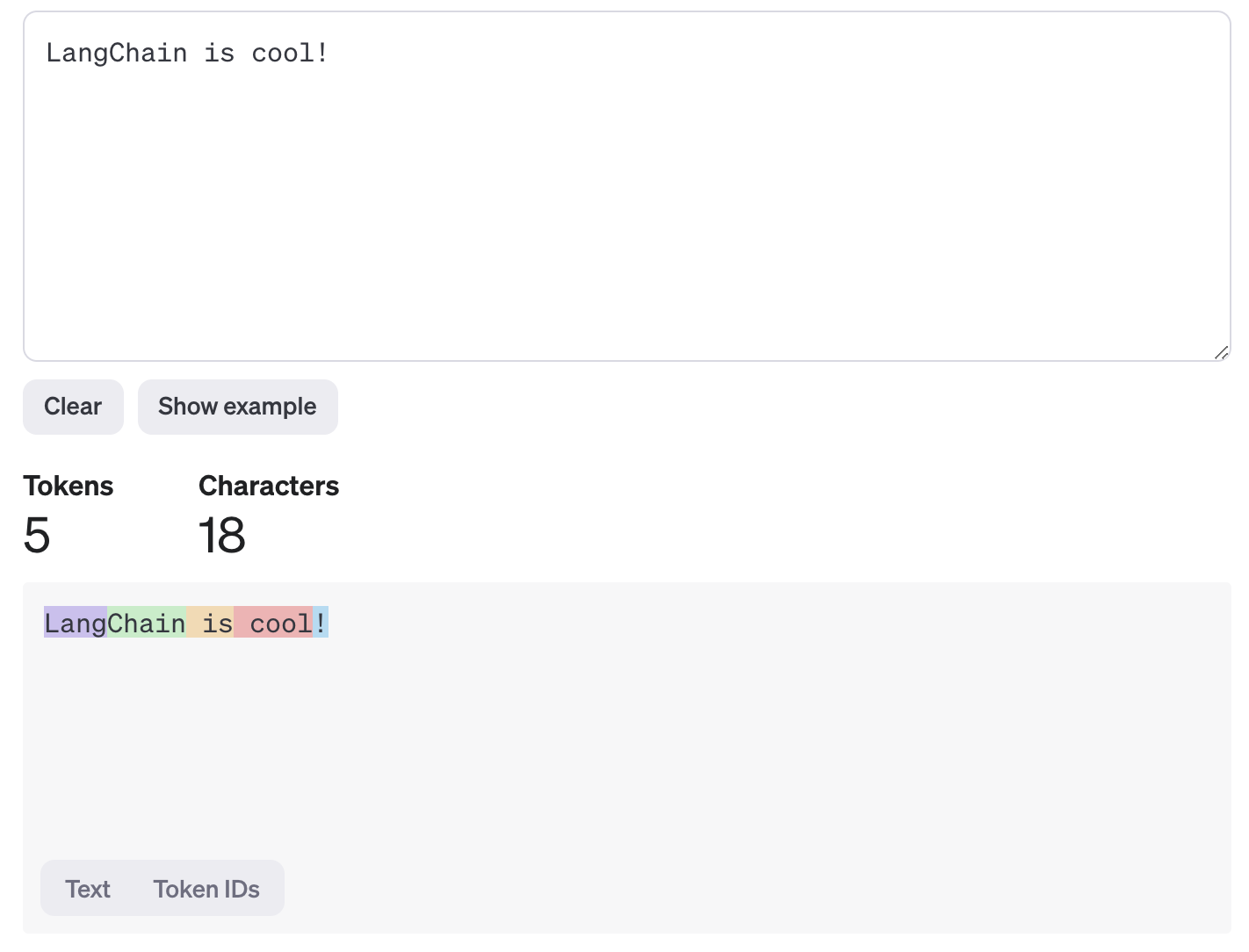
-
处理:这些模型背后的 transformer 架构按顺序处理 tokens,以预测句子中的下一个 token。它通过分析 tokens 之间的关系,从输入中捕捉上下文和意义来实现这一点。
-
输出生成:模型一次生成一个新的 token。然后,这些输出 token 会被解码回人类可读的文本。
使用 tokens 而不是原始字符可以让模型专注于语言上有意义的单元,这有助于它更有效地捕捉语法、结构和上下文。
tokens 不一定是文本
尽管 tokens 最常用于表示文本,但它们不一定仅限于文本数据。Tokens 还可以作为 多模态数据 的抽象表示,例如:
- 图像,
- 音频,
- 视频,
- 以及其他类型的数据。
在写作时,几乎没有模型支持 多模态输出,只有少数模型能够处理 多模态输入(例如,文本与图像或音频的组合)。然而,随着人工智能的不断进步,我们预计 多模态 将变得更加普�遍。这将使模型能够处理和生成更广泛的媒体,从而大大扩展 tokens 所能代表的范围以及模型如何与各种数据类型进行交互。
原则上,任何可以表示为 token 序列的东西 都可以用类似的方式进行建模。例如,DNA 序列——由一系列核苷酸(A、T、C、G)组成——可以被分词和建模,以捕捉模式、进行预测或生成序列。这种灵活性使基于 transformer 的模型能够处理各种类型的序列数据,从而在其在生物信息学、信号处理以及涉及结构化或非结构化序列的其他领域的潜在应用中进行扩展。
有关多模态输入和输出的更多信息,请参阅 multimodality 部分。
为什么不使用字符?
使用 tokens 而不是单个字符可以使模型更高效,并更好地理解上下文和语法。Tokens 代表有意义的单元��,如完整的单词或单词的一部分,这使得模型能够比处理原始字符更有效地捕捉语言结构。Token 级别的处理还减少了模型需要处理的单元数量,从而加快了计算速度。
相比之下,字符级处理需要处理更长的输入序列,使得模型更难学习关系和上下文。Tokens 使模型能够专注于语言含义,从而在生成响应时更加准确和高效。
tokens 如何对应于文本
有关 tokens 如何计数以及它们如何对应于文本的更多详细信息,请参阅 OpenAI 的这篇帖子。
根据 OpenAI 的帖子,英语文本的近似 token 计数如下:
- 在英语中,1 个 token ~= 4 个字符
- 1 个 token ~= ¾ 个单词
- 100 个 token ~= 75 个单词